
소프트맥스
우리는 무언가를 분류할 때 맞다 아니다(True/False)만 분류하는 것이 아니라 상, 중, 하로 분류하기도 하고 동물의 사진을 보고 강아지, 고양이, 토끼, 앵무새 등으로 분류하기도 한다. 그렇게 클래스가 여러개인 경우에도 0~1로 표현해주는 시그모이드 함수를 이용해 클래스를 분류하도록 하는 메소드가 소프트맥스다.
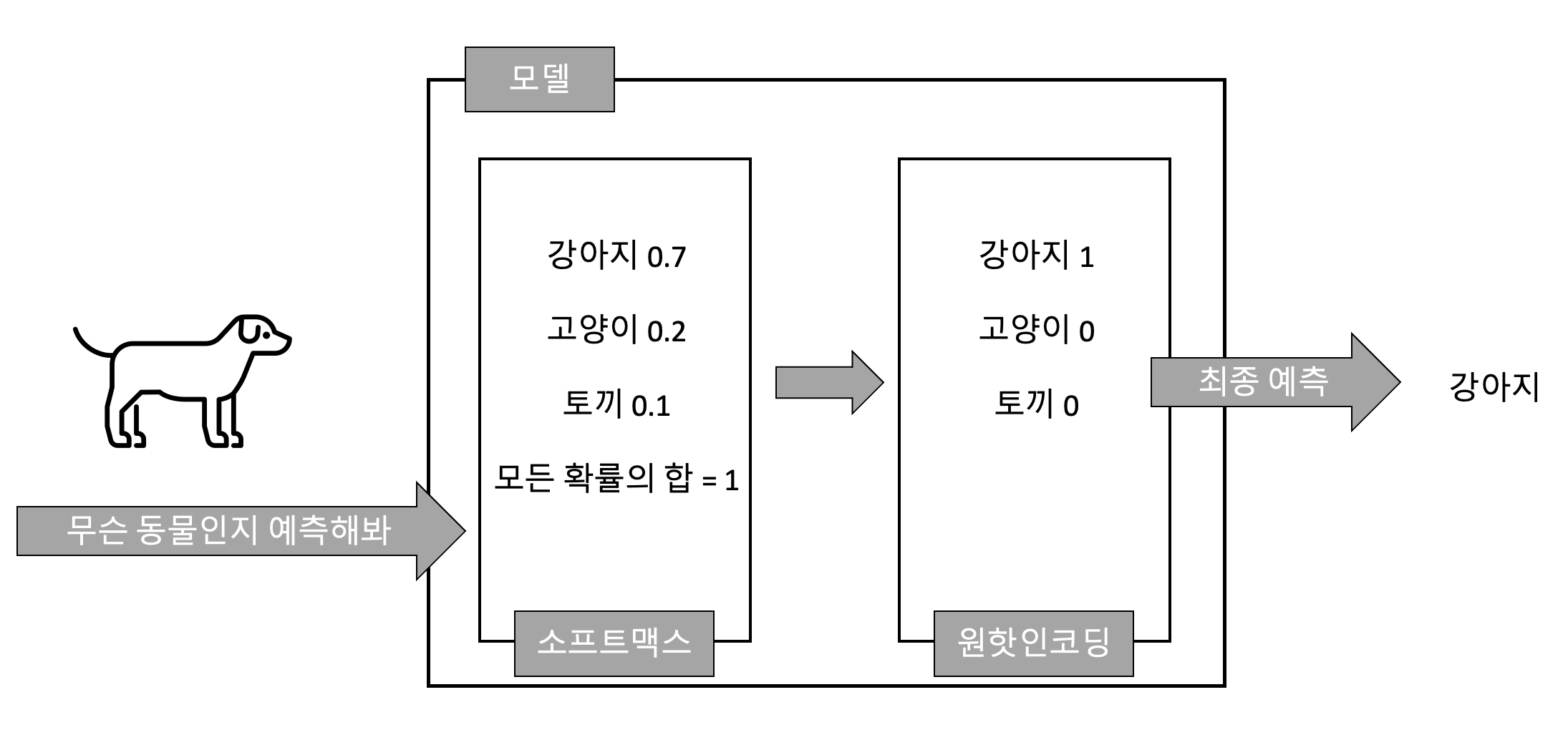
예를 들어 동물들의 사진을 두고 예측해보라고 했을 때 소프트맥스는 해당 동물이 강아지일 확률 0.7, 고양이일 확률 0.2, 토끼일 확률 0.1로 표현하여 모든 값을 더했을 때 1이 되도록 값을 출력해준다. 소프트맥스로 확률값을 구한 이후에 '원-핫인코딩'을 이용해서 제일 큰 값을 1로 나머지 값은 0으로 변환한다. 결론적으로 이 동물은 강아지라고 결정하게된다.
# 필요한 라이브러리 가져오기
import tensorflow as tf
import numpy as np
tf.random.set_seed(777) # for reproducibility
print(tf.__version__)tf.random.set_seed(777)은 앞선 코드 예제에서 사용하고 설명도 했었는데, 랜덤함수를 사용하는 경우 재실행 했을 때 값이 랜덤하게 바뀌지 않고 이전과 동일한 환경에서 실행할 수 있도록 해주는 코드다. 자세한 설명은 아래 링크에서 확인 가능하다.
[코드] 단순회귀분석(Simple Linear Regression)을 TensorFlow로 구현하기 실습.쥬피터
# 데이터 세트 만들기
x_data = [[1, 2, 1, 1],
[2, 1, 3, 2],
[3, 1, 3, 4],
[4, 1, 5, 5],
[1, 7, 5, 5],
[1, 2, 5, 6],
[1, 6, 6, 6],
[1, 7, 7, 7]]
y_data = [[0, 0, 1],
[0, 0, 1],
[0, 0, 1],
[0, 1, 0],
[0, 1, 0],
[0, 1, 0],
[1, 0, 0],
[1, 0, 0]]
# 데이터 세트 타입을 numpy 형식으로 변경
x_data = np.asarray(x_data, dtype=np.float32)
y_data = np.asarray(y_data, dtype=np.float32)데이터세트를 만들었다.
x_data는 4개의 변수에 대한 값을 가진 8개의 데이터,
y_data는 8개의 데이터에 대한 결과값이 3개 중에 하나임을 확인할 수 있다.
np.asarray()
이후 코딩을 더 편리하게 할 수 있도록 x, y데이터들을 numpy형식으로 변경했다.
nb_classes = 3
print(x_data.shape)
print(y_data.shape)
nb_classes에 예측값의 클래스 수인 3개를 넣어주었다.
x_data.shape
x_data와 y_data의 모양을 확인할 수 있는 코드로 변수의 형태에 따라 .shape에서 그 모양을 확인할 수 있다.
이번에는 2차원 데이터이기 때문에 x_data.shape는 (8, 4)의 결과, y_data.shape는 (8, 3)의 결과가 출력된다.
#Weight and bias setting
W = tf.Variable(tf.random.normal((4, nb_classes)), name='weight')
b = tf.Variable(tf.random.normal((nb_classes,)), name='bias')
variables = [W, b]
print(W,b)tf.Variable(tf.random.normal((4, nb_classes))
우리가 알고있는 함수는 딱 하나, Wx + b 라는 일차식에 넣어줄 W값과 b값을 세팅해줬다.
코드를 하나씩 풀이해보자면
tf에 있는 메소드 사용할 예정인데
Variable 그 값은 변동 가능성이 있다. 변동가능성이 있는 그 숫자들은 뭐냐면 (괄호)안에 있는 값들이다.
()괄호 안에 tf에 있는 메소드를 이용해서 숫자를 넣을껀데
random 랜덤한 숫자를 넣어줄꺼고
normal 정규분포로부터 불러올꺼다. 얼마나 불러올꺼냐면 (괄호)안에 있는 크기만큼 불러올꺼다.
(4, nb_classes) 이 부분은 데이터 세트에 맞춰서 설정하면 되는데 나는 여기서 x_data의 피쳐개수 4개와 각 클래스에 해당하는 값 3개(nb_classes)가 나올 수 있도록 결과적으로 (4, 3)의 형태로 불러왔다.
W의 경우에는 가중치라서 (4, 3)의 형태로 가져왔고, b는 편향이기 때문에 값은 한개만 필요해서 (nb_classes, )로 넣었다.
b의 값을 작성할 때 주의할 점은 형태를 맞추기 위해서 값을 2개를 넣어줘야하는데 나는 nb_classes하나만 필요했기 때문에 콤마 이후에는 값을 따로 작성해서 넣지 않았다. 여기서 콤마를 삭제하고 실행하면 형태가 다르다는 오류가 발생한다.
print(W, b)를 통해 W의 shape은 (4, 3) b의 shape는 (3, )이라는 것을 확인할 수 있다.
def hypothesis(X):
return tf.nn.softmax(tf.matmul(X, W) + b)
print(hypothesis(x_data))tf.nn.softmax(tf.matmul(X, W) + b)
소프트맥스를 사용하는 함수를 하나 만들어줬다.
tf에 nn에 있는 softmax를 사용할 예정인데 어떤 데이터에 사용할 예정이냐면 (괄호)안에 있는 데이터를 사용할 예정이다.
(괄호)안의 데이터는 tf에 있는 matmul()을 이용해 텐서 사이의 행렬의 곱을 계산해줄 예정이다.
우리가 알고있는 함수를 보면 Wx + b이기 때문에 W와 x값이 서로 곱해져야 함을 알 수 있고, matmul()을 이용해 곱셈을 계산해준다.
hypothesis(x_data)
만들어 둔 함수 hypothesis에 X값으로 x_data를 넣어준다.
그럼 각 x값에 대하여 Wx + b함수식을 계산한 값이 결과물로 출력된다.
# 샘플데이터 적용시켜보기
# Softmax onehot test
sample_db = [[8,2,1,4]]
sample_db = np.asarray(sample_db, dtype=np.float32)
print(hypothesis(sample_db))샘플데이터를 만들고, 계산하기 편하게 numpy형식으로 변환한 이후 hypothesis 함수를 적용시켰다.
tf.Tensor([[0.00283937 0.03048898 0.9666716 ]], shape=(1, 3), dtype=float32)
이렇게 출력이 되었는데 확인해보면 샘플데이터의 값으로는 y클래스 3개중에 첫번째 값이 될 확률은 0.0028, 두번째 값이 될 확률은 0.03, 세번째 값이 될 확률은 0.96으로 샘플데이터는 세번째 값이라고 예측하는 것을 확인할 수 있다. 또한 총 출력값들의 합이 1이 되는 것도 확인할 수 있다.
코드실습 다른 글
[코드] 단순회귀분석(Simple Linear Regression)을 TensorFlow로 구현하기 실습.쥬피터
[코드] 로지스틱회귀(Logistic Regression)를 TensorFlow로 구현하기 실습.쥬피터
'ML&DL > Project' 카테고리의 다른 글
| [코드] keras에서 제공하는 fashion mnist 이미지 분류모델 실습.쥬피터 (0) | 2021.12.10 |
|---|---|
| 내가 하려고 정리한 빅데이터 프로젝트 주제 (= 데이터분석 프로젝트 주제 = 머신러닝 프로젝트 주제) (0) | 2021.10.25 |
| [코드] 로지스틱회귀(Logistic Regression)를 TensorFlow로 구현하기 실습.쥬피터 (0) | 2021.09.24 |
| [코드] 단순회귀분석(Simple Linear Regression)을 TensorFlow로 구현하기 실습.쥬피터 (1) | 2021.09.13 |
| 빅데이터 프로젝트 3. 결과 발표 (3) | 2021.07.09 |
