
데이터 분석에서 분류 알고리즘은 True/False로 결과를 나타내거나 카테고리로 나누는 경우 사용할 수 있다. 이미 알고있는 데이터의 레이블값을 통해 새로운 데이터가 어떤것으로 분류되는지 예측하는것이라고 할 수 있다.
분류 알고리즘 종류
- 나이브 베이즈
- 로지스틱 회귀
- 결정 트리
- 최소 근접 알고리즘(kNN)
- 서포트 벡터 머신(SVM)
- 신경망
- 앙상블
이 포스팅에서는 결정트리, 앙상블에 대해서만 다루려고 한다.
결정트리
가장 직관적인 알고리즘으로 가장 효율적인 규칙을 찾아 분류하는 알고리즘이다.
결정트리는 루트노드, 규칙노드, 리프노드로 이루어져 있고, 가능한 적은 규칙노드로 높은 예측 정확도를 가지는 것이 목표다.
아래는 예시를 들어봤다.
루트노드에 사과, 초콜릿, 바구니, 손수건이라는 데이터가 있고 이 데이터들을 분리해보려고 한다.
규칙노드는 각 데이터의 특성을 보고 정하면 좋다.
이 그림은 이해를 돕기 위해 간단하게 정리한 것이지 실제로는 각 노드 안에 규칙, 지니계수, 데이터개수 등의 정보가 존재한다.

결정트리에 사용되는 파라미터는 다음과 같다.
min_samples_split : 노드를 분할하기 위한 최소한의 샘플 데이터 수 (디폴트2)
min_samples_leaf : 말단 노드가 되기 위한 최소한의 샘플 데이터 수
max_features : 최적의 분할을 위해 고려할 최대 피처 개수
max_depth : 트리의 최대 깊이를 규정 (몇개의 규칙노드를 만들것인가를 정함)
위의 예시에서 min_samples_split 파라미터에 3을 넣어주면 리프노드를 더 빨리 만나게된다.
루트노드 : 사과, 초콜릿, 바구니, 손수건
규칙노드 : 먹을 수 있는가?
리프노드 : 사과, 초콜릿 / 바구니, 손수건
왜냐하면 마지막 노드가 가지고 있는 데이터 수는 2개인데 파라미터에서는 3개 이상의 데이터가 있을 경우 분리를 할 수 있다고 설정해주었기 때문이다.
비슷하게 min_samples_leaf 파라미터에 1을 넣어주면 리프노드를 더 나중에 만나게 된다.
위 그림처럼 리프노드에 있는 데이터 개수가 1개가 될 때 까지 계속 규칙을 찾아서 분류해준다.
max_depth의 경우 가장 자주 쓰이는 파라미터다.
데이터가 엄청 많고 복잡한 경우에는 규칙이 너무 많아져서 오히려 너무 많은 분류가 일어나고, 이는 학습데이터에게만 딱 맞는 트리가 생성되어 과적합이 된다. 이 때 적당한 제어로 트리의 크기를 결정해주는 파라미터가 max_depth 파라미터다.
앙상블
앙상블은 여러가지의 알고리즘을 합쳐놓은 것을 의미한다.
같은 데이터에 대해서 결정트리 + 랜덤포레스트 + 로지스틱 회귀를 사용한것도 앙상블
원본 데이터를 여러개로 쪼개서 데이터1에 대한 결정트리 + 데이터2에 대한 결정트리 + 데이터3에 대한 결정트리도 앙상블이라고 한다.
동일한 혹은 다른 알고리즘을 합친 앙상블들은 3가지 유형으로 나눌 수 있다.
1. 보팅
2. 배깅
3. 부스팅
보팅(voting)
보팅은 투표하다 vote에서 나온 단어로 다시 하드 보팅과 소프트 보팅으로 나뉜다.
하드보팅은 다수결의 원칙과 비슷해서 다양한 알고리즘이 예측한 값 중 가장 많이 나온 값을 최종 결정한다.
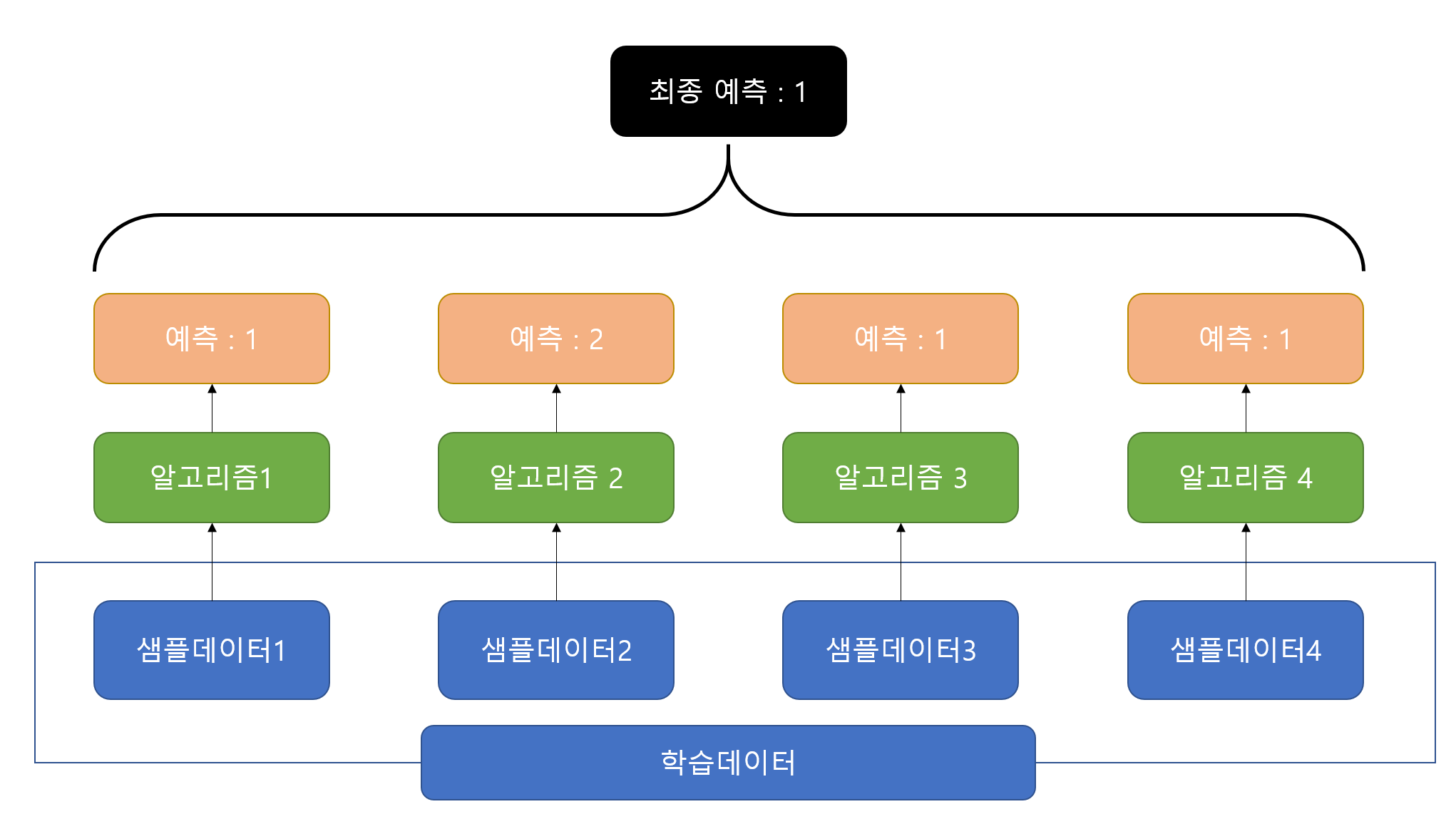
소프트보팅은 각 예측값이 나올 확률들의 평균을 구해서 그 평균값이 높은 값을 최종적으로 결정한다.
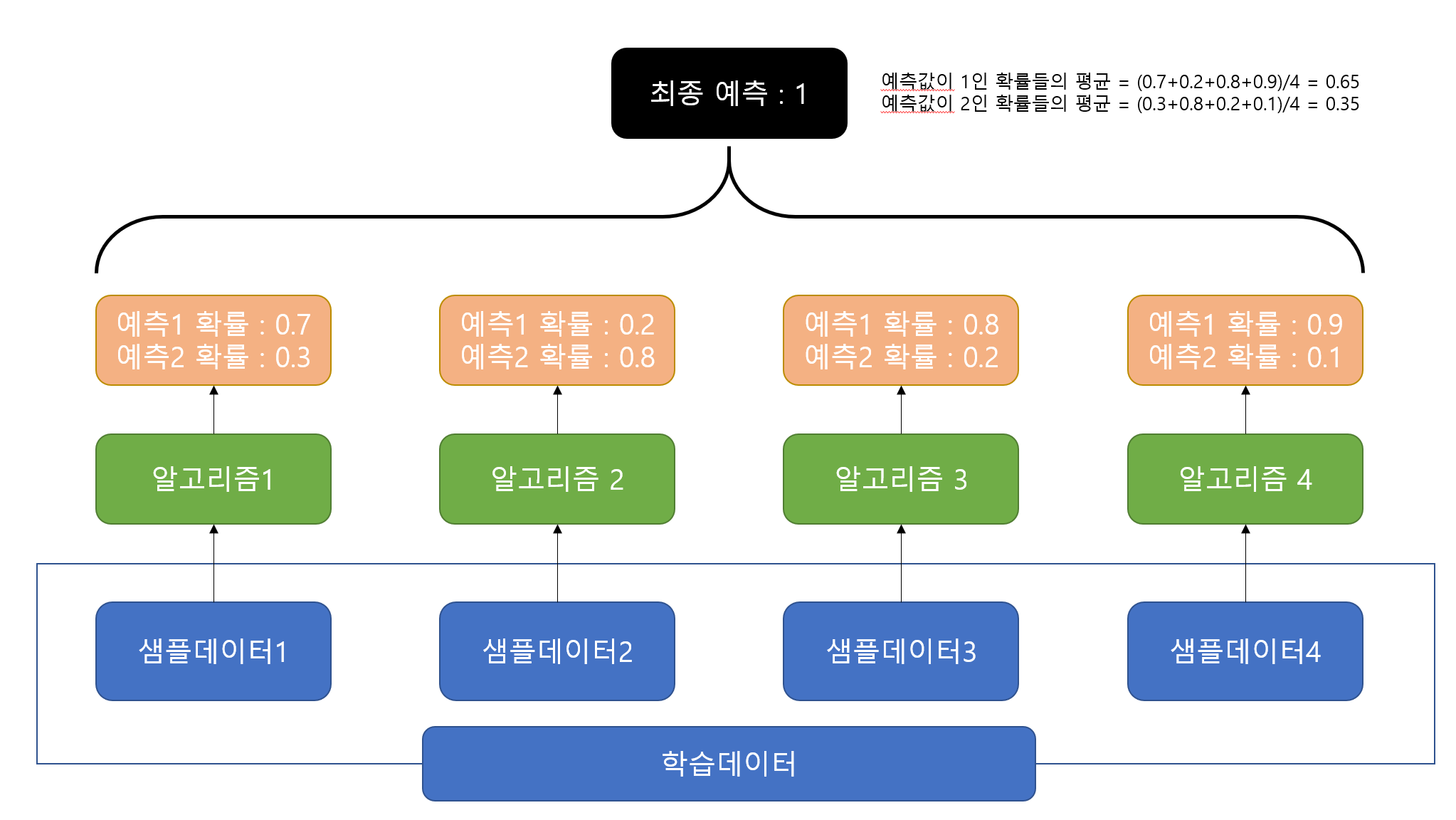
배깅(bagging)
배깅은 bootstrap aggregating의 약자로 bootstrap은 학습데이터를 이용해 여러개의 샘플데이터를 만든다는 뜻이고 aggregating은 집계한다는 뜻이다. 여기서 샘플데이터를 만들 때는 서로 중첩된 값이 존재하도록 만들어야 한다.
대표적인 배깅형 앙상블 알고리즘으로는 랜덤포레스트가 있다.
랜덤포레스트는 여러개의 결정트리와 소프트보팅을 합친 앙상블 알고리즘이다.
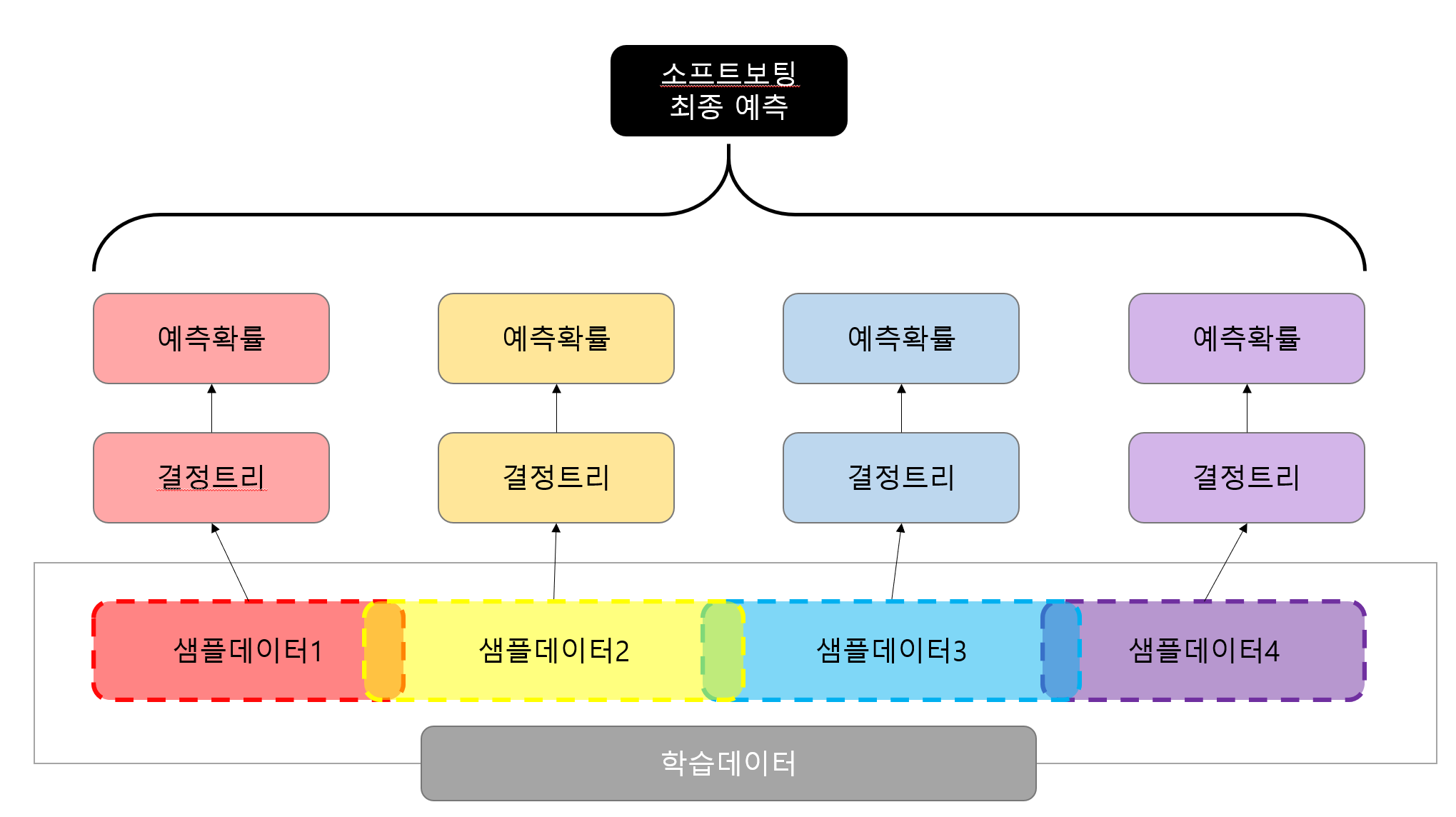
어떤 예측 결과를 원하는가?
누군가가 데이터를 주고 분석해주세요 하는 경우 어떤 분석결과를 원하는지, 분석을 통해 얻고자 하는 것이 무엇인지 확인해야 분석의 방향성을 잡을 수 있다.
어떤 분석 알고리즘을 이용할것인가?
통상적으로 예측값을 숫자로 나타내거나 연속성이 있으면 회귀 분석을,
True/False나 카테고리별로 예측하는 경우 분류 분석을 이용한다.
1. 결정트리
데이터형식에 크게 영향을 받지 않고 직관적이고 빠르다.
결정트리 알고리즘만 단독으로 사용하는 경우에는 과적합이 되는 경향이 있어 대부분 앙상블로 이용한다.
2. 랜덤 포레스트
결정트리의 단점을 보완한 앙상블로 회귀와 분류 모두 가장 많이 사용한다.
다만 텍스트 데이터 같이 매우 차원이 높고 희소한 데이터에는 잘 작동하지 않는다.
3. GBM
4. XGBoost
5. LightGBM
'ML&DL > study' 카테고리의 다른 글
| 파이썬 머신러닝 05. 회귀 (0) | 2021.08.04 |
|---|---|
| 파이썬 머신러닝 04-4. 분류 알고리즘 (앙상블 부스팅) (0) | 2021.08.03 |
| 파이썬 머신러닝 04-2. 언더피팅, 오버피팅과 해결방안 (0) | 2021.07.26 |
| 파이썬 머신러닝 04-1. Mac에 Graghviz 설치하기 (0) | 2021.07.20 |
| 파이썬 머신러닝 03. 평가 (0) | 2021.07.19 |
